
Node.js 基础概念
Node.js 是一个基于 Chrome V8 JavaScript 引擎构建的 JavaScript 运行时环境。简单来说,Node.js 让 JavaScript 可以在服务器端运行,而不仅仅局限于浏览器中。
Node.js 的核心特点
1. 单线程事件循环
- Node.js 使用单线程的事件循环模型
- 通过事件驱动和回调函数处理并发请求
- 避免了传统多线程编程中的线程切换开销
2. 非阻塞 I/O
- 所有 I/O 操作(文件读写、网络请求等)都是异步的
- 当等待 I/O 操作完成时,程序不会被阻塞,可以继续处理其他任务
- 大大提高了应用程序的吞吐量
3. 跨平台
- 支持 Windows、macOS、Linux 等多种操作系统
- 一次编写,到处运行
4. 丰富的生态系统
- npm(Node Package Manager)拥有数百万个开源包
- 活跃的开发者社区
与传统服务器端技术的区别
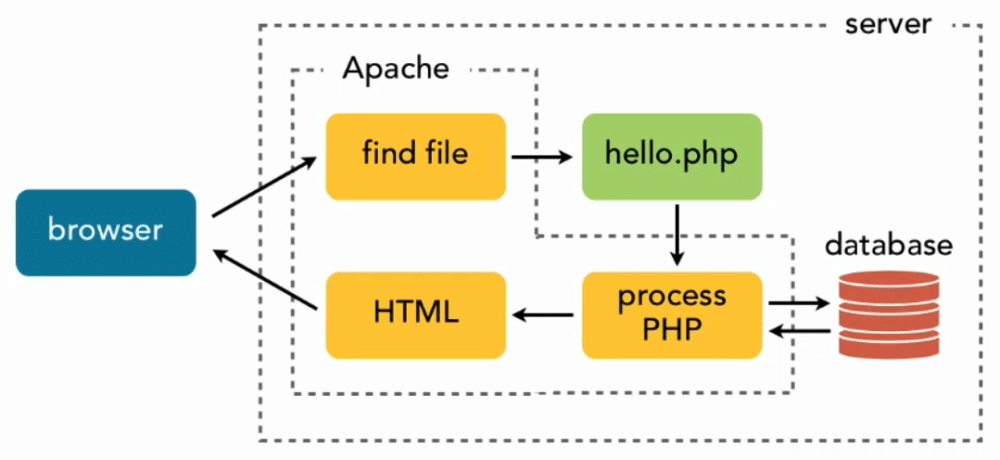
1、传统服务器端技术(如 Apache + PHP):
请求1 → 创建线程1 → 处理请求 → 返回响应 → 销毁线程1 请求2 → 创建线程2 → 处理请求 → 返回响应 → 销毁线程2 请求3 → 创建线程3 → 处理请求 → 返回响应 → 销毁线程3
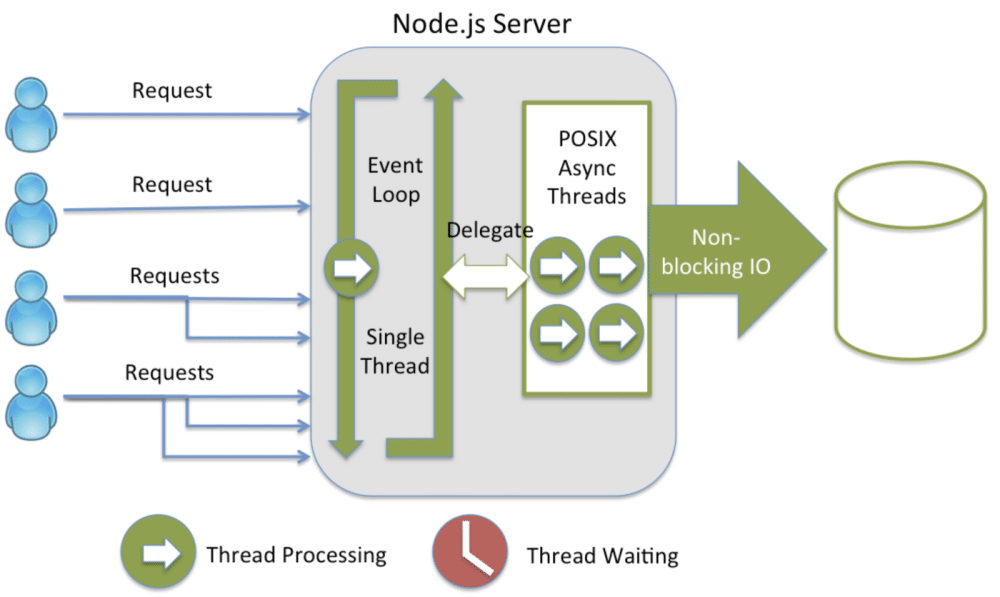
2、Node.js 的处理方式:
请求1 → 事件循环 → 处理请求 → 返回响应 请求2 → 事件循环 → 处理请求 → 返回响应 (复用同一线程) 请求3 → 事件循环 → 处理请求 → 返回响应
| 特性 | 传统多线程模型 | Node.js 单线程模型 |
|---|---|---|
| 内存占用 | 每个线程占用 2MB 左右 | 单线程,内存占用少 |
| 并发处理 | 线程数量限制并发数 | 事件循环处理高并发 |
| 上下文切换 | 频繁的线程切换开销 | 无线程切换开销 |
| 编程复杂度 | 需要处理线程同步 | 避免了锁和线程同步问题 |
| 适用场景 | CPU 密集型任务 | I/O 密集型任务 |
Node.js 的应用场景
1、适合的应用场景
Web 应用程序
- RESTful API 服务
- 单页应用(SPA)的后端服务
- 实时 Web 应用
实时应用
- 聊天应用
- 在线游戏
- 协作工具(如在线文档编辑)
微服务架构
- 轻量级的微服务
- API 网关
- 服务间通信
工具和命令行应用
- 构建工具(如 Webpack、Gulp)
- 脚手架工具
- 自动化脚本
物联网(IoT)应用
- 设备数据收集
- 传感器数据处理
2、不适合的应用场景
CPU 密集型任务
- 图像/视频处理
- 复杂的数学计算
- 大数据分析
需要大量计算的应用
- 机器学习训练
- 科学计算
- 加密货币挖矿
事件驱动和非阻塞 I/O 模型
传统阻塞 I/O 模型示例:
实例
// 每次 readFileSync 都会"卡住"程序,等待文件读取完成后才继续往下执行
const data1 = readFileSync('file1.txt'); // 程序在此暂停,等待读取完成
const data2 = readFileSync('file2.txt'); // data1 读完后,再暂停等待
const data3 = readFileSync('file3.txt'); // data2 读完后,再暂停等待
console.log('所有文件读取完成'); // 三个文件全部读完后才执行到这里
// 总耗时 = 读取file1的时间 + 读取file2的时间 + 读取file3的时间
Node.js 非阻塞 I/O 模型示例:
实例
const fs = require('fs');
// 三个读文件的操作几乎同时发出,程序不会等待任何一个完成
fs.readFile('file1.txt', (err, data1) => {
// 这个回调函数会在 file1.txt 读取完成后自动被调用
console.log('文件1读取完成');
});
fs.readFile('file2.txt', (err, data2) => {
// 这个回调函数会在 file2.txt 读取完成后自动被调用
console.log('文件2读取完成');
});
fs.readFile('file3.txt', (err, data3) => {
// 这个回调函数会在 file3.txt 读取完成后自动被调用
console.log('文件3读取完成');
});
// 注意:这行代码会最先执行!因为上面三个读文件操作是异步的,
// 发出读取请求后程序立刻继续往下走,不会等待文件读取完成
console.log('程序继续执行,不等待文件读取');
// 实际输出顺序示例:
// 程序继续执行,不等待文件读取 ← 最先打印
// 文件2读取完成 ← 哪个文件先读完就先打印,顺序不固定
// 文件1读取完成
// 文件3读取完成
// 总耗时 ≈ 三个文件中读取最慢的那一个的时间(并发执行,而非顺序叠加)
事件循环机制:
事件循环是 Node.js 实现非阻塞 I/O 的核心机制。它持续运行,不断检查是否有待执行的任务,从而实现"单线程处理并发"的效果:
- 调用栈(Call Stack):执行同步代码,函数调用时入栈,执行完毕后出栈
- 事件队列(Event Queue):存储异步操作完成后的回调函数,等待调用栈空闲时依次执行
- 事件循环(Event Loop):持续监控调用栈和事件队列,一旦调用栈为空,就将事件队列中的回调取出放入调用栈执行
事件循环按照固定顺序依次处理以下几个阶段:
┌───────────────────────────┐
┌─>│ timers │ ← 执行 setTimeout、setInterval 的到期回调
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ pending callbacks │ ← 执行上一轮循环中延迟的 I/O 回调(如某些系统错误回调)
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ idle, prepare │ ← Node.js 内部使用,开发者一般不需要关心
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ poll │ ← 核心阶段:获取新的 I/O 事件并执行其回调(如文件读取、网络请求完成)
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ check │ ← 执行 setImmediate 的回调(在 poll 阶段之后立即执行)
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
└──┤ close callbacks │ ← 执行关闭事件的回调,如 socket.on('close', ...)
└───────────────────────────┘
对于初学者来说,最需要记住的是:同步代码总是优先执行,异步回调(如文件读取完成的处理)会在调用栈清空后才被执行。
JavaScript 运行时环境
V8 引擎简介
V8 是 Google 开发的高性能 JavaScript 引擎,也是 Chrome 浏览器的核心组件。
Node.js 使用 V8 引擎来执行 JavaScript 代码。
V8 引擎的特点:
即时编译(JIT)
- 将 JavaScript 代码直接编译为机器码
- 无需中间字节码,执行效率更高
垃圾收集
- 自动内存管理,开发者无需手动释放内存
- 使用分代垃圾收集算法,将内存分为新生代和老生代分别管理,提升回收效率
优化技术
- 内联缓存(Inline Caching):缓存对象属性的查找结果,避免重复查找
- 隐藏类(Hidden Classes):将动态语言的对象结构静态化,加速属性访问
- 动态优化:运行时分析热点代码并进行针对性优化
浏览器 JavaScript vs Node.js JavaScript
虽然都使用 JavaScript 语言,但运行环境的差异导致了一些重要区别:
相同点:
- 都使用相同的 JavaScript 语法
- 都支持 ES6+ 特性
- 都使用 V8 引擎(Chrome 浏览器)
不同点:
| 特性 | 浏览器 JavaScript | Node.js JavaScript |
|---|---|---|
| 全局对象 | window |
global |
| 模块系统 | ES6 modules, AMD | CommonJS, ES6 modules |
| 文件系统访问 | 不可访问(出于安全限制) | 完全访问 |
| 网络请求 | XMLHttpRequest, Fetch | http, https 模块 |
| DOM 操作 | 支持(操作页面元素) | 不支持(服务器端无页面) |
| 进程控制 | 不支持 | 支持(可读取环境变量、退出进程等) |
浏览器环境示例:
实例
console.log(window); // 浏览器全局对象,包含所有浏览器 API
document.getElementById('app'); // 通过 ID 获取页面元素(Node.js 中不可用)
localStorage.setItem('key', 'value'); // 浏览器本地存储(Node.js 中不可用)
Node.js 环境示例:
实例
console.log(global); // Node.js 全局对象(对应浏览器中的 window)
const fs = require('fs'); // 引入内置文件系统模块(浏览器中不可用)
fs.readFile('data.txt', 'utf8', callback); // 读取服务器本地文件(浏览器中不可用)
全局对象的差异
浏览器中的全局对象:
实例
console.log(this === window); // true,顶层 this 就是 window 对象
var globalVar = 'hello';
console.log(window.globalVar); // 'hello',用 var 声明的变量会成为 window 的属性
Node.js 中的全局对象:
实例
// 注意:Node.js 中每个文件都是一个独立的模块,模块内的 this 不等于 global
console.log(this === global); // false(在模块作用域中,this 指向 module.exports)
var globalVar = 'hello';
console.log(global.globalVar); // undefined,模块内的变量不会自动挂载到 global
// Node.js 中的模块作用域
console.log(this); // {} 空对象,即 module.exports 的初始值
console.log(module.exports === this); // true,模块内 this 指向 module.exports
Node.js 特有的全局变量:
实例
console.log(__filename); // 当前模块文件的绝对路径,例如:/home/user/project/app.js
console.log(process); // 进程对象,可读取命令行参数(process.argv)、环境变量(process.env)等
console.log(Buffer); // 用于处理二进制数据的构造函数,常用于文件读写和网络通信
Node.js 的优势与局限
优势详解
1. 高并发处理能力
传统多线程服务器处理 10,000 个并发连接需要约 20GB 内存(每个线程约 2MB),而 Node.js 只需要很少的内存就能处理相同数量的连接。
实例
const http = require('http');
const server = http.createServer((req, res) => {
// 模拟异步操作(如查询数据库),100ms 后返回响应
// 在这 100ms 内,事件循环可以继续处理其他请求,不会被阻塞
setTimeout(() => {
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('Hello World\n');
}, 100);
});
server.listen(3000, () => {
console.log('服务器运行在 http://localhost:3000/');
});
// 得益于非阻塞 I/O 和事件循环机制,这个服务器可以同时处理数千个请求而不会阻塞
2. 快速开发
统一的 JavaScript 语言栈(前端和后端都用 JavaScript)使得前后端开发更加高效。开发者只需掌握一门语言,就可以同时编写前端和后端代码,并且可以在两端之间共享代码逻辑:
实例
function validateEmail(email) {
const regex = /^[^\s@]+@[^\s@]+\.[^\s@]+$/;
return regex.test(email);
}
// 前端使用(浏览器中运行):用户提交表单时先在前端校验,避免无效请求发到服务器
if (validateEmail(userInput)) {
// 验证通过,发送到服务器
}
// 后端使用(Node.js 中运行):服务器再次校验,防止绕过前端直接请求接口
if (validateEmail(req.body.email)) {
// 验证通过,保存到数据库
}
3. 统一语言栈的优势
- 代码复用:前后端可以共享工具函数、数据验证逻辑、常量定义等
- 团队效率:开发人员可以同时负责前后端开发,减少沟通成本
- 技术栈简化:只需掌握 JavaScript 一门语言,降低学习成本和技术复杂度
4. 丰富的 npm 生态系统
# npm 提供了数百万个开源包,几乎任何功能都能找到现成的库 npm search express # 搜索名为 express 的包 npm install express # 安装 express 包到当前项目 npm update # 更新当前项目中所有包到最新兼容版本
局限性分析
1. CPU 密集型任务的性能问题
实例
// fibonacciSync 是纯计算任务,会一直占用 CPU,期间事件循环无法处理其他请求
function fibonacciSync(n) {
if (n < 2) return n;
return fibonacciSync(n - 1) + fibonacciSync(n - 2);
}
// 这会阻塞整个应用长达数秒,期间所有请求都无法响应
console.log(fibonacciSync(40));
// 解决方案:使用 Worker Threads 将 CPU 密集型任务放到独立线程中执行,
// 主线程的事件循环就不会被阻塞
const { Worker, isMainThread, parentPort, workerData } = require('worker_threads');
if (isMainThread) {
// 主线程:创建一个 Worker,并将参数 { n: 40 } 传给它
// Worker 会在独立线程中执行当前这个文件(__filename 指当前文件路径)
const worker = new Worker(__filename, {
workerData: { n: 40 }
});
// 监听 Worker 发来的消息(计算结果)
worker.on('message', (result) => {
console.log('结果:', result); // Worker 计算完成后,主线程在这里接收结果
});
} else {
// Worker 线程:通过 workerData 获取主线程传入的参数,执行计算后发送结果
const result = fibonacciSync(workerData.n);
parentPort.postMessage(result); // 将结果发送回主线程
}
2. 回调地狱问题
实例
fs.readFile('file1.txt', (err, data1) => {
if (err) throw err;
fs.readFile('file2.txt', (err, data2) => { // 嵌套第一层
if (err) throw err;
fs.readFile('file3.txt', (err, data3) => { // 嵌套第二层
if (err) throw err;
// 实际项目中这种嵌套可能有十几层,严重影响代码维护性
console.log('所有文件读取完成');
});
});
});
// 现代解决方案:使用 Promise + async/await,让异步代码写起来像同步代码一样直观
const fsPromises = require('fs').promises;
async function readFiles() {
try {
// await 会等待每个文件读取完成,但整个函数不会阻塞事件循环
// 注意:这里是顺序读取,如需并发读取多个文件,可以使用 Promise.all()
const data1 = await fsPromises.readFile('file1.txt');
const data2 = await fsPromises.readFile('file2.txt');
const data3 = await fsPromises.readFile('file3.txt');
console.log('所有文件读取完成');
} catch (err) {
// try/catch 可以统一处理所有异步错误,不需要在每个回调里单独判断
console.error('读取文件失败:', err);
}
}
3. 单线程的脆弱性
实例
// 与多线程不同,单线程中一个未处理的错误会让整个服务停止
setTimeout(() => {
throw new Error('未捕获的异常'); // 这会导致整个应用崩溃,所有请求都无法响应
}, 1000);
// 解决方案:注册全局异常处理器,在应用崩溃前记录日志并优雅地退出
process.on('uncaughtException', (err) => {
console.error('未捕获的异常:', err);
// 此处应先记录错误日志,再退出,避免静默崩溃导致问题难以排查
process.exit(1); // 退出码 1 表示异常退出
});
process.on('unhandledRejection', (reason, promise) => {
// 当 Promise 被 reject 但没有 .catch() 处理时触发
console.error('未处理的 Promise 拒绝:', reason);
process.exit(1);
});
适用场景分析
1、RESTful API 服务
实例
// 首先需要安装 express:npm install express
const express = require('express');
const app = express();
app.use(express.json()); // 中间件:自动解析请求体中的 JSON 数据
// GET 请求:获取用户列表(对应 HTTP 方法 GET,路径 /api/users)
app.get('/api/users', (req, res) => {
const users = [
{ id: 1, name: '张三' },
{ id: 2, name: '李四' }
];
res.json(users); // 以 JSON 格式返回数据
});
// POST 请求:创建新用户(客户端在请求体中传入用户信息)
app.post('/api/users', (req, res) => {
const newUser = req.body; // 获取客户端发来的 JSON 数据
// 实际项目中这里通常会将用户信息保存到数据库
res.status(201).json({ message: '用户创建成功', user: newUser });
});
// PUT 请求:更新指定用户信息(:id 是路由参数,如 /api/users/1 表示更新 ID 为 1 的用户)
app.put('/api/users/:id', (req, res) => {
const { id } = req.params; // 从路径中获取用户 ID
const updatedData = req.body; // 从请求体中获取更新内容
res.json({ message: `用户 ${id} 更新成功`, data: updatedData });
});
// DELETE 请求:删除指定用户
app.delete('/api/users/:id', (req, res) => {
const { id } = req.params;
res.json({ message: `用户 ${id} 删除成功` });
});
app.listen(3000, () => {
console.log('API 服务器运行在 http://localhost:3000/');
});
2、实时应用
实例
// 首先需要安装:npm install socket.io
const io = require('socket.io')(server);
// 监听客户端连接事件,每有新用户连接就触发一次
io.on('connection', (socket) => {
// 监听当前连接的客户端发来的 'chat message' 事件
socket.on('chat message', (msg) => {
io.emit('chat message', msg); // 将消息广播给所有在线客户端(包括发送者)
});
});
3、中间件和代理服务
实例
// 将前端发来的 /api/xxx 请求转发到后端真实 API 服务器,隐藏真实地址,常用于解决跨域问题
// 首先需要安装:npm install http-proxy-middleware
const httpProxy = require('http-proxy-middleware');
const proxy = httpProxy({
target: 'http://api.example.com', // 真实后端 API 服务器地址
changeOrigin: true, // 修改请求头中的 Host 为 target 地址
pathRewrite: {
'^/api': '' // 将路径中的 /api 前缀去掉再转发,例如 /api/users → /users
}
});