
Pandas 数据结构 - Series
Series 是 Pandas 中的一个核心数据结构,类似于一个一维的数组,具有数据和索引。
Series 可以存储任何数据类型(整数、浮点数、字符串等),并通过标签(索引)来访问元素。
Series 的数据结构是非常有用的,因为它可以处理各种数据类型,同时保持了高效的数据操作能力,比如可以通过标签来快速访问和操作数据。
Series 特点:
一维数组:Series 中的每个元素都有一个对应的索引值。
索引: 每个数据元素都可以通过标签(索引)来访问,默认情况下索引是从 0 开始的整数,但你也可以自定义索引。
数据类型:
Series可以容纳不同数据类型的元素,包括整数、浮点数、字符串、Python 对象等。大小不变性:Series 的大小在创建后是不变的,但可以通过某些操作(如 append 或 delete)来改变。
操作:Series 支持各种操作,如数学运算、统计分析、字符串处理等。
缺失数据:Series 可以包含缺失数据,Pandas 使用NaN(Not a Number)来表示缺失或无值。
自动对齐:当对多个 Series 进行运算时,Pandas 会自动根据索引对齐数据,这使得数据处理更加高效。

实例
# 创建一个Series对象,指定名称为'A',值分别为1, 2, 3, 4
# 默认索引为0, 1, 2, 3
series = pd.Series([1, 2, 3, 4], name='A')
# 显示Series对象
print(series)
# 如果你想要显式地设置索引,可以这样做:
custom_index = [1, 2, 3, 4] # 自定义索引
series_with_index = pd.Series([1, 2, 3, 4], index=custom_index, name='A')
# 显示带有自定义索引的Series对象
print(series_with_index)
输出结果为:
0 1 1 2 2 3 3 4 Name: A, dtype: int64 1 1 2 2 3 3 4 4 Name: A, dtype: int64
Series 是 Pandas 中的一种基本数据结构,类似于一维数组或列表,但具有标签(索引),使得数据在处理和分析时更具灵活性。
以下是关于 Pandas 中的 Series 的详细介绍。
创建 Series
可以使用 pd.Series() 构造函数创建一个 Series 对象,传递一个数据数组(可以是列表、NumPy 数组等)和一个可选的索引数组。
pandas.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)
参数说明:
data:Series 的数据部分,可以是列表、数组、字典、标量值等。如果不提供此参数,则创建一个空的 Series。index:Series 的索引部分,用于对数据进行标记。可以是列表、数组、索引对象等。如果不提供此参数,则创建一个默认的整数索引。dtype:指定 Series 的数据类型。可以是 NumPy 的数据类型,例如np.int64、np.float64等。如果不提供此参数,则根据数据自动推断数据类型。name:Series 的名称,用于标识 Series 对象。如果提供了此参数,则创建的 Series 对象将具有指定的名称。copy:是否复制数据。默认为 False,表示不复制数据。如果设置为 True,则复制输入的数据。fastpath:是否启用快速路径。默认为 False。启用快速路径可能会在某些情况下提高性能。
创建一个简单的 Series 实例:
实例
a = [1, 2, 3]
myvar = pd.Series(a)
print(myvar)
输出结果如下:
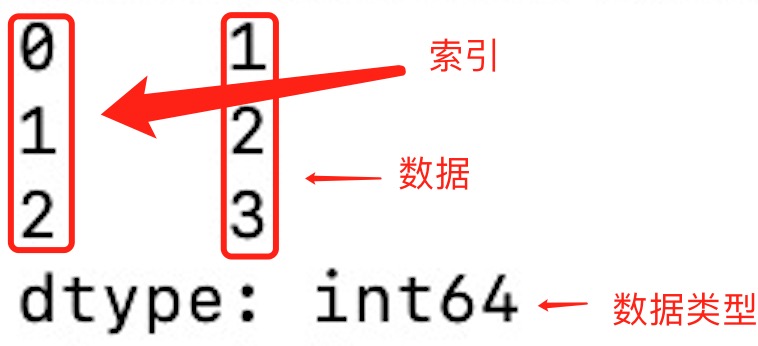
从上图可知,如果没有指定索引,索引值就从 0 开始,我们可以根据索引值读取数据:
实例
a = [1, 2, 3]
myvar = pd.Series(a)
print(myvar[1])
输出结果如下:
2
我们可以指定索引值,如下实例:
实例
a = ["Google", "Runoob", "Wiki"]
myvar = pd.Series(a, index = ["x", "y", "z"])
print(myvar)
输出结果如下:

根据索引值读取数据:
实例
a = ["Google", "Runoob", "Wiki"]
myvar = pd.Series(a, index = ["x", "y", "z"])
print(myvar["y"])
输出结果如下:
Runoob
我们也可以使用 key/value 对象,类似字典来创建 Series:
实例
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites)
print(myvar)
输出结果如下:

从上图可知,字典的 key 变成了索引值。
如果我们只需要字典中的一部分数据,只需要指定需要数据的索引即可,如下实例:
实例
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites, index = [1, 2])
print(myvar)
输出结果如下:

设置 Series 名称参数:
实例
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites, index = [1, 2], name="RUNOOB-Series-TEST" )
print(myvar)

Series 方法
下面是 Series 中一些常用的方法:
| 方法名称 | 功能描述 |
|---|---|
index | 获取 Series 的索引 |
values | 获取 Series 的数据部分(返回 NumPy 数组) |
head(n) | 返回 Series 的前 n 行(默认为 5) |
tail(n) | 返回 Series 的后 n 行(默认为 5) |
dtype | 返回 Series 中数据的类型 |
shape | 返回 Series 的形状(行数) |
describe() | 返回 Series 的统计描述(如均值、标准差、最小值等) |
isnull() | 返回一个布尔 Series,表示每个元素是否为 NaN |
notnull() | 返回一个布尔 Series,表示每个元素是否不是 NaN |
unique() | 返回 Series 中的唯一值(去重) |
value_counts() | 返回 Series 中每个唯一值的出现次数 |
map(func) | 将指定函数应用于 Series 中的每个元素 |
apply(func) | 将指定函数应用于 Series 中的每个元素,常用于自定义操作 |
astype(dtype) | 将 Series 转换为指定的类型 |
sort_values() | 对 Series 中的元素进行排序(按值排序) |
sort_index() | 对 Series 的索引进行排序 |
dropna() | 删除 Series 中的缺失值(NaN) |
fillna(value) | 填充 Series 中的缺失值(NaN) |
replace(to_replace, value) | 替换 Series 中指定的值 |
cumsum() | 返回 Series 的累计求和 |
cumprod() | 返回 Series 的累计乘积 |
shift(periods) | 将 Series 中的元素按指定的步数进行位移 |
rank() | 返回 Series 中元素的排名 |
corr(other) | 计算 Series 与另一个 Series 的相关性(皮尔逊相关系数) |
cov(other) | 计算 Series 与另一个 Series 的协方差 |
to_list() | 将 Series 转换为 Python 列表 |
to_frame() | 将 Series 转换为 DataFrame |
iloc[] | 通过位置索引来选择数据 |
loc[] | 通过标签索引来选择数据 |
实例
# 创建 Series
data = [1, 2, 3, 4, 5, 6]
index = ['a', 'b', 'c', 'd', 'e', 'f']
s = pd.Series(data, index=index)
# 查看基本信息
print("索引:", s.index)
print("数据:", s.values)
print("数据类型:", s.dtype)
print("前两行数据:", s.head(2))
# 使用 map 函数将每个元素加倍
s_doubled = s.map(lambda x: x * 2)
print("元素加倍后:", s_doubled)
# 计算累计和
cumsum_s = s.cumsum()
print("累计求和:", cumsum_s)
# 查找缺失值(这里没有缺失值,所以返回的全是 False)
print("缺失值判断:", s.isnull())
# 排序
sorted_s = s.sort_values()
print("排序后的 Series:", sorted_s)
输出结果为:
索引: Index(['a', 'b', 'c', 'd', 'e', 'f'], dtype='object') 数据: [1 2 3 4 5 6] 数据类型: int64 前两行数据: a 1 b 2 dtype: int64 元素加倍后: a 2 b 4 c 6 d 8 e 10 f 12 dtype: int64 累计求和: a 1 b 3 c 6 d 10 e 15 f 21 dtype: int64 缺失值判断: a False b False c False d False e False f False dtype: bool 排序后的 Series: a 1 b 2 c 3 d 4 e 5 f 6 dtype: int64
更多 Series 说明
使用列表、字典或数组创建一个默认索引的 Series。
# 使用列表创建 Series
s = pd.Series([1, 2, 3, 4])
# 使用 NumPy 数组创建 Series
s = pd.Series(np.array([1, 2, 3, 4]))
# 使用字典创建 Series
s = pd.Series({'a': 1, 'b': 2, 'c': 3, 'd': 4})
基本操作:
# 指定索引创建 Series
s = pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])
# 获取值
value = s[2] # 获取索引为2的值
print(s['a']) # 返回索引标签 'a' 对应的元素
# 获取多个值
subset = s[1:4] # 获取索引为1到3的值
# 使用自定义索引
value = s['b'] # 获取索引为'b'的值
# 索引和值的对应关系
for index, value in s.items():
print(f"Index: {index}, Value: {value}")
# 使用切片语法来访问 Series 的一部分
print(s['a':'c']) # 返回索引标签 'a' 到 'c' 之间的元素
print(s[:3]) # 返回前三个元素
# 为特定的索引标签赋值
s['a'] = 10 # 将索引标签 'a' 对应的元素修改为 10
# 通过赋值给新的索引标签来添加元素
s['e'] = 5 # 在 Series 中添加一个新的元素,索引标签为 'e'
# 使用 del 删除指定索引标签的元素。
del s['a'] # 删除索引标签 'a' 对应的元素
# 使用 drop 方法删除一个或多个索引标签,并返回一个新的 Series。
s_dropped = s.drop(['b']) # 返回一个删除了索引标签 'b' 的新 Series
基本运算:
# 算术运算 result = series * 2 # 所有元素乘以2 # 过滤 filtered_series = series[series > 2] # 选择大于2的元素 # 数学函数 import numpy as np result = np.sqrt(series) # 对每个元素取平方根
计算统计数据:使用 Series 的方法来计算描述性统计。
print(s.sum()) # 输出 Series 的总和 print(s.mean()) # 输出 Series 的平均值 print(s.max()) # 输出 Series 的最大值 print(s.min()) # 输出 Series 的最小值 print(s.std()) # 输出 Series 的标准差
属性和方法:
# 获取索引 index = s.index # 获取值数组 values = s.values # 获取描述统计信息 stats = s.describe() # 获取最大值和最小值的索引 max_index = s.idxmax() min_index = s.idxmin() # 其他属性和方法 print(s.dtype) # 数据类型 print(s.shape) # 形状 print(s.size) # 元素个数 print(s.head()) # 前几个元素,默认是前 5 个 print(s.tail()) # 后几个元素,默认是后 5 个 print(s.sum()) # 求和 print(s.mean()) # 平均值 print(s.std()) # 标准差 print(s.min()) # 最小值 print(s.max()) # 最大值
使用布尔表达式:根据条件过滤 Series。
print(s > 2) # 返回一个布尔 Series,其中的元素值大于 2
查看数据类型:使用 dtype 属性查看 Series 的数据类型。
print(s.dtype) # 输出 Series 的数据类型
转换数据类型:使用 astype 方法将 Series 转换为另一种数据类型。
s = s.astype('float64') # 将 Series 中的所有元素转换为 float64 类型
注意事项:
Series中的数据是有序的。- 可以将
Series视为带有索引的一维数组。 - 索引可以是唯一的,但不是必须的。
- 数据可以是标量、列表、NumPy 数组等。