
正则表达式 - 简介
正则表达式(Regular Expression,简称 regex 或 regexp)是一种强大的文本处理工具,它使用一种特殊的字符串来描述、匹配一系列符合某个句法规则的字符串。
你可以把它想象成一个 超级通配符,普通的通配符(如 * 代表任意字符)功能有限,而正则表达式则能定义极其复杂和精确的文本模式,从简单的单词匹配到复杂的结构化数据提取,无所不能。
例如,您很可能使用 ? 和 * 通配符来查找硬盘上的文件。? 通配符匹配文件名中的 0 个或 1 个字符,而 * 通配符匹配零个或多个字符。像 data(\w)?\.dat 这样的模式将查找下列文件:
使用 * 字符代替 ? 字符扩大了找到的文件的数量。data.*\.dat 匹配下列所有文件:
尽管这种搜索方法很有用,但它还是有限的。通过理解 * 通配符的工作原理,引入了正则表达式所依赖的概念,但正则表达式功能更强大,而且更加灵活。
正则表达式的使用,可以通过简单的办法来实现强大的功能。下面先给出一个简单的示例:
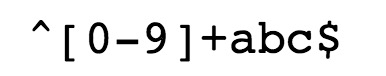
-
^ 为匹配输入字符串的开始位置。
-
[0-9]+匹配多个数字, [0-9] 匹配单个数字,+ 匹配一个或者多个。
-
abc$匹配字母 abc 并以 abc 结尾,$ 为匹配输入字符串的结束位置。
我们在写用户注册表单时,只允许用户名包含字符、数字、下划线和连接字符 -,并设置用户名的长度,我们就可以使用以下正则表达式来设定。
^[a-zA-Z0-9_-]{3,15}$
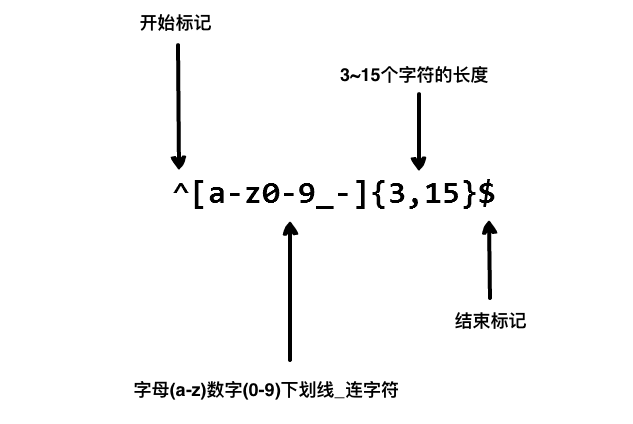
^表示匹配字符串的开头。[a-zA-Z0-9_-]表示字符集,包含小写字母、大写字母、数字、下划线和连接字符 -。{3,15}表示前面的字符集最少出现 3 次,最多出现 15 次,从而限制了用户名的长度在 3 到 15 个字符之间。$表示匹配字符串的结尾。
以上的正则表达式可以匹配 runoob、runoob1、run-oob、run_oob, 但不匹配 ru,因为它包含的字母太短了,小于 3 个无法匹配。也不匹配 runoob$, 因为它包含特殊字符。

实例
匹配以数字开头,并以 abc 结尾的字符串。:
以下标记的文本是获得的匹配的表达式:
尝试一下 »
正则表达式元字符和特性
字符匹配
- 普通字符:普通字符按照字面意义进行匹配,例如匹配字母 "a" 将匹配到文本中的 "a" 字符。
- 元字符:元字符具有特殊的含义,例如
\d匹配任意数字字符,\w匹配任意字母数字字符,.匹配任意字符(除了换行符)等。
量词
*:匹配前面的模式零次或多次。+:匹配前面的模式一次或多次。?:匹配前面的模式零次或一次。{n}:匹配前面的模式恰好 n 次。{n,}:匹配前面的模式至少 n 次。{n,m}:匹配前面的模式至少 n 次且不超过 m 次。
字符类
[ ]:匹配括号内的任意一个字符。例如,[abc]匹配字符 "a"、"b" 或 "c"。[^ ]:匹配除了括号内的字符以外的任意一个字符。例如,[^abc]匹配除了字符 "a"、"b" 或 "c" 以外的任意字符。
边界匹配
^:匹配字符串的开头。$:匹配字符串的结尾。\b:匹配单词边界。\B:匹配非单词边界。
分组和捕获
( ):用于分组和捕获子表达式。(?: ):用于分组但不捕获子表达式。
特殊字符
\:转义字符,用于匹配特殊字符本身。.:匹配任意字符(除了换行符)。|:用于指定多个模式的选择。
正则表达式的定义与用途
从技术上讲,正则表达式是一个由普通字符(例如字母 a 到 z)和特殊字符(称为元字符)组成的字符串,这个字符串构成了一个 搜索模式(pattern),该模式被用来在文本中进行搜索、匹配、替换或分割操作。
主要用途
正则表达式主要有三大用途:
- 文本搜索与匹配:快速判断一段文本中是否包含符合特定模式的子串。例如,检查一个字符串是否是一个有效的电子邮件地址格式。
- 文本替换:将文本中所有匹配特定模式的部分替换为新的内容。例如,将一篇文档中所有的日期格式从
YYYY-MM-DD统一改为MM/DD/YYYY。 - 文本提取与分割:从一大段文本中精确地提取出我们关心的部分,或者根据特定的分隔符将文本切分成数组。例如,从日志文件中提取所有的 IP 地址,或者用逗号分割一个 CSV 字符串。
正则表达式的应用场景
正则表达式几乎渗透在编程和日常文本处理的方方面面。下面是一些最常见的应用场景:
1. 数据验证
这是正则表达式最经典的应用之一,确保用户输入的数据符合预期的格式。
- 验证邮箱地址:检查输入是否像
username@domain.com。 - 验证手机号码:检查是否符合国家/地区的手机号格式(如中国的 11 位数字)。
- 验证密码强度:要求密码必须包含大小写字母、数字和特殊字符。
- 验证日期格式:确保日期是
2023-12-25或12/25/2023等有效格式。 - 验证身份证号:匹配特定编码规则的身份证号码。
2. 文本搜索与过滤
在大量文本中快速定位信息。
- 日志分析:在服务器日志中搜索所有
ERROR或WARN级别的记录。 - 代码搜索:在 IDE 或编辑器中,使用正则表达式搜索所有函数定义(如
function xxx(...))或特定变量名。 - 文档内容查找:在长文档中查找所有出现的电话号码或网址。
3. 文本替换与清洗
批量修改文本内容,使其规范化。
- 格式化数据:将电话号码从
12345678901格式化为123-4567-8901。 - 清理数据:移除文本中多余的空白字符(如多个连续空格或制表符)。
- 敏感信息脱敏:将文本中的身份证号替换为
***,如110101199001011234->110101********1234。 - 代码重构:批量重命名变量或函数名。
4. 文本提取与解析
从非结构化的文本中提取结构化的数据。
- 网页爬虫:从 HTML 代码中提取所有的链接 (
href="...") 或图片地址 (src="...")。 - 解析配置文件:读取
key = value格式的配置文件。 - 提取特定数据:从一段文本中提取所有出现的金额(如
¥100.50或$99.99)。
5. 字符串分割
使用复杂的规则,而不仅仅是单个字符,来分割字符串。
- 使用一个或多个空格、逗号或分号来分割一个句子。
- 根据不同的分隔符(如
,、;、\t)来解析 CSV 或 TSV 数据。
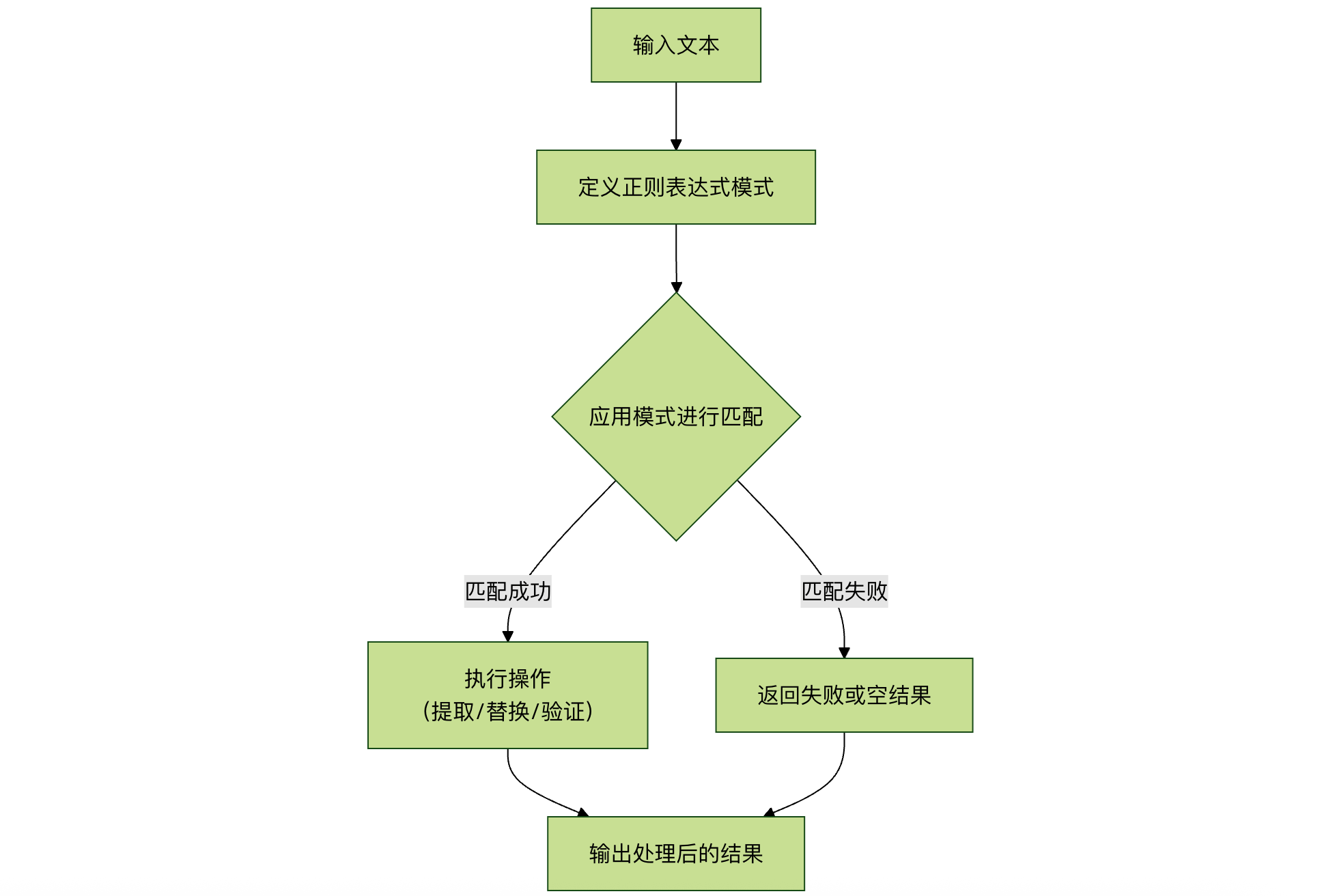
下面的流程图概括了正则表达式在数据处理中的核心工作流程:
发展历史
正则表达式的祖先可以一直上溯至对人类神经系统如何工作的早期研究。Warren McCulloch 和 Walter Pitts 这两位神经生理学家研究出一种数学方式来描述这些神经网络。
1951 年, 一位叫 Stephen Kleene 的数学家在 McCulloch 和 Pitts 早期工作的基础上,发表了一篇标题为《神经网事件的表示法》的论文,引入了正则表达式的概念。正则表达式就是用来描述他称为正则集的代数的表达式,因此采用正则表达式这个术语。
随后,发现可以将这一工作应用于使用 Ken Thompson 的计算搜索算法的一些早期研究,Ken Thompson 是 Unix 的主要发明人。正则表达式的第一个实用应用程序就是 Unix 中的 grep 编辑器。
大致发展历史如下:
1951年:计算理论的奠基人之一,美国计算机科学家Stephen Kleene首次提出了正则语言的概念,并使用形式化的方法来描述这种语言。这为正则表达式的发展奠定了理论基础。
1960年代:Ken Thompson,Unix操作系统的共同创始人之一,开发了第一个实际应用正则表达式的程序,它是Unix中grep命令的一部分。这标志着正则表达式的实际应用。
1970年代:Ken Thompson和Rob Pike开发了第一个正则表达式引擎,在Unix系统中广泛使用,这对正则表达式的普及起到了关键作用。
1986年:Philip Hazel开发了PCRE(Perl Compatible Regular Expressions)库,它是一种正则表达式库,允许在不同编程语言中使用Perl风格的正则表达式。
1997年:IEEE发布了POSIX.2标准,其中包括了正则表达式的标准规范,这使得正则表达式在不同Unix系统中的行为更加一致。
2000年代以后:正则表达式在计算机编程和文本处理中变得越来越流行,支持正则表达式的编程语言和工具变得更加丰富和强大,如Perl、Python、Java、JavaScript等。
当前:正则表达式仍然是文本处理和数据提取的重要工具,它在数据科学、文本分析、网络爬虫、字符串搜索和替换等领域都有广泛的应用。
应用领域
目前,正则表达式已经在很多软件中得到广泛的应用,包括 *nix(Linux, Unix等)、HP 等操作系统,PHP、C#、Java 等开发环境,以及很多的应用软件中,都可以看到正则表达式的影子。
C# 正则表达式
在我们的 C# 教程中,C# 正则表达式 这一章节专门介绍了有关 C# 正则表达式的知识。
Java 正则表达式
在我们的 Java 教程中,Java 正则表达式 这一章节专门介绍了有关 Java 正则表达式的知识。
JavaScript 正则表达式
在我们的 JavaScript 教程中,JavaScript RegExp 对象 这一章节专门介绍了有关 JavaScript 正则表达式的知识,同时我们还提供了完整的 JavaScript RegExp 对象参考手册。
Python 正则表达式
在我们的 Python 基础教程中,Python 正则表达式 这一章节专门介绍了有关 Python 正则表达式的知识。
Ruby 正则表达式
在我们的 Ruby 教程中,Ruby 正则表达式 这一章节专门介绍了有关 Ruby 正则表达式的知识。
| 命令或环境 | . | [ ] | ^ | $ | \( \) | \{ \} | ? | + | | | ( ) |
| vi | √ | √ | √ | √ | √ | |||||
| Visual C++ | √ | √ | √ | √ | √ | |||||
| awk | √ | √ | √ | √ | awk是支持该语法的,只是要在命令 行加入 --posix or --re-interval参数即可,可见 man awk中的interval expression | √ | √ | √ | √ | |
| sed | √ | √ | √ | √ | √ | √ | ||||
| delphi | √ | √ | √ | √ | √ | √ | √ | √ | √ | |
| python | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ |
| java | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ |
| javascript | √ | √ | √ | √ | √ | √ | √ | √ | √ | |
| php | √ | √ | √ | √ | √ | |||||
| perl | √ | √ | √ | √ | √ | √ | √ | √ | √ | |
| C# | √ | √ | √ | √ | √ | √ | √ | √ |
下面是一个主流编程语言中正则表达式支持的对比:
| 编程语言 | 支持方式 | 常用类/模块 | 简单示例(匹配数字) |
|---|---|---|---|
| JavaScript | 语言原生支持 | RegExp 对象,或使用字面量 /.../ |
/\d+/ 或 new RegExp("\\d+") |
| Python | 标准库 re 模块 |
re 模块 |
re.compile(r"\d+") |
| Java | 标准库 java.util.regex 包 |
Pattern 和 Matcher 类 |
Pattern.compile("\\d+") |
| PHP | 内置 PCRE 函数 | preg_ 系列函数(如 preg_match) |
preg_match("/\d+/", $text) |
| C# | System.Text.RegularExpressions 命名空间 |
Regex 类 |
new Regex(@"\d+") |
| Go | 标准库 regexp 包 |
regexp 包 |
regexp.MustCompile(\d+) |
| Ruby | 语言原生支持,核心类 | Regexp 类 |
/\d+/ |