
Skills 工作原理
你可能会好奇:智能体又不是人,它怎么知道某个 Skill 能做什么、该怎么做?
答案很简单——靠读文件。
每个 Skill 背后,都有一个描述文件,通常叫 SKILL.md,就像一份说明书。
Skills 的工作原理
Skills 使用渐进式披露(Progressive Disclosure)的方式,让代理在不同的阶段加载不同详细程度的信息。这种设计使得代理可以同时管理大量技能,而不会耗尽上下文空间。
三个阶段
代理加载技能分为以下三个阶段:
-
1. 发现阶段(Discovery):当对话开始时,代理会扫描所有可用的技能文件夹,只读取每个技能的名称(name)和描述(description)。这是最轻量的信息,足以让代理判断某个技能是否可能与当前任务相关。
-
2. 激活阶段(Activation):
当代理判断某个技能的描述与用户请求相匹配时,会将完整的 SKILL.md 文件内容加载到上下文中。这时代理会读取完整的指令和说明。 -
3. 执行阶段(Execution):代理按照 SKILL.md 中的指令执行任务。在这个过程中,代理可能会调用技能附带的脚本、读取参考资料或使用其他资源。
渐进式加载的优势
| 阶段 | 加载内容 | 典型大小 |
|---|---|---|
| 发现阶段 | name + description | 约 100 tokens |
| 激活阶段 | 完整 SKILL.md | 建议不超过 5000 tokens |
| 执行阶段 | 脚本、参考资料等 | 按需加载 |
智能体在执行任务之前,会先读这份说明书,搞清楚三件事:
- 这个 Skill 能干什么?(能力描述)
- 要用它,我需要提供什么?(输入参数)
- 做这件事有什么规矩?(环境约束和注意事项)
读完之后,智能体就知道:哦,这个 Skill 适合用来解决当前的问题,我来调用它。
下面这张图展示了这个过程:
Skill 执行流程
从用户指令开始,先进行 Skill 意图识别,决定是否进入受控执行路径。
命中 Skill 后,系统加载 SKILL.md,建立工具权限与行为边界,再结合上下文进行推理。
只有在确实需要时才调用被允许的外部工具,否则在规则内完成逻辑。
最终结果经过约束整合后输出,用户的下一次输入触发新一轮完整流程。
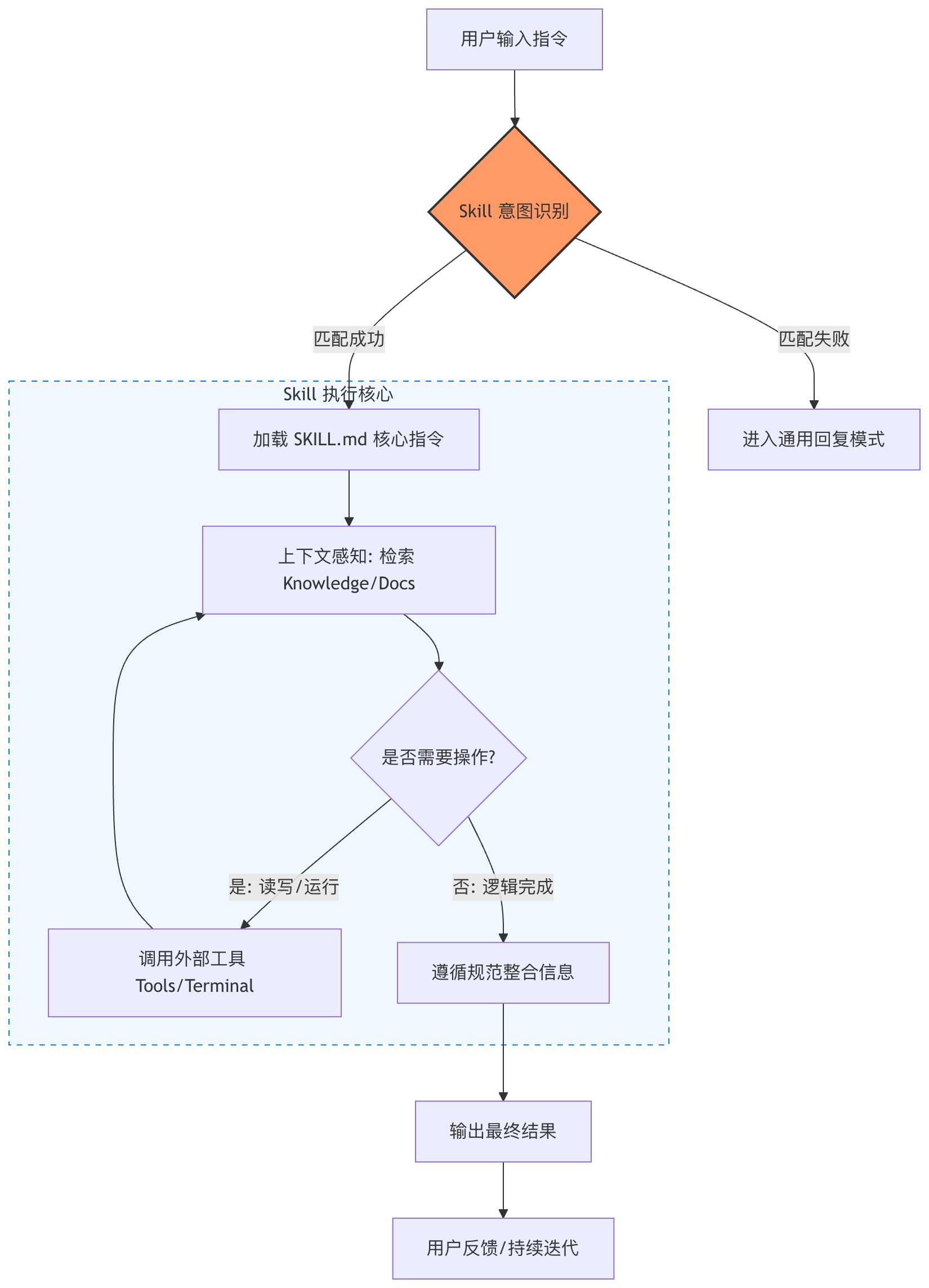
Skills 工作过程
用户提出需求后,Agent 首先理解任务内容,然后分析应该使用哪些能力(Skills)完成工作。
Skill 可以理解为一个独立能力模块或插件,例如天气查询、搜索、文件处理、数据库访问等。
Agent 负责思考和决策,Skill 负责执行动作,执行完成后结果再返回给 Agent,由 Agent 整理成用户容易理解的结果并输出。
整个流程形成一个完整闭环:理解 → 决策 → 执行 → 返回结果。

| 步骤 | 阶段 | Agent 内部动作 | 示例 |
|---|---|---|---|
| ① | 用户发起请求 | 接收自然语言任务 | "帮我查询北京今天的天气" |
| ② | 理解用户意图 | 分析用户真正想做什么,并提取参数 | 动作:查询;类型:天气;地点:北京 |
| ③ | 制定执行计划 | 拆分任务步骤 | 找天气服务 → 获取天气数据 → 整理结果 |
| ④ | 选择 Skill | 匹配最适合的能力模块 | 选择 Weather Skill |
| ⑤ | 执行 Skill | 调用外部工具或 API | 请求天气接口 |
| ⑥ | 获取执行结果 | 接收 Skill 返回的数据 | 温度、湿度、空气质量 |
| ⑦ | 生成最终回复 | 整理并转换为自然语言 | "北京今天晴,18℃~30℃" |
| ⑧ | 返回给用户 | 输出最终结果 | 用户看到完整回复 |
Skill 类型:
| Skill 类型 | 功能说明 | 常见场景 |
|---|---|---|
| 搜索 Skill | 查询外部信息 | 搜索新闻、知识问答 |
| 天气 Skill | 获取天气数据 | 天气查询 |
| 文件 Skill | 读取文件内容 | PDF、Word、Excel |
| 数据分析 Skill | 数据计算和统计 | 报表分析 |
| 数据库 Skill | 查询数据库 | MySQL、PostgreSQL |
| 浏览器 Skill | 自动操作网页 | 自动登录、爬取内容 |
| 代码 Skill | 执行代码 | Python、Node.js |
| 图像 Skill | 图像处理能力 | OCR、图片生成 |