
归并排序
归并排序(英语:Merge sort,或mergesort),是建立在归并操作上的一种有效的排序算法。
归并排序是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
想象一下,你要整理一副完全打乱的扑克牌。一个高效的方法是:先把这副牌分成两小堆,分别把每一小堆整理好,最后再把这两堆已经有序的牌合并成一整副有序的牌。归并排序 正是基于这种 分而治之 思想的经典排序算法。
它的核心操作可以概括为两个步骤:
- 分:递归地将一个大的无序列表,不断地从中间劈开,分解成若干个小的子列表,直到每个子列表只包含一个元素(一个元素的列表自然是有序的)。
- 治:递归地将这些有序的子列表两两合并,在合并的过程中进行排序,最终合并成一个完整的有序列表。
适用说明
归并排序适用于数据量大,并且对稳定性有要求的场景。
归并排序是一种 稳定 的排序算法(即相等元素的相对顺序在排序后保持不变),其时间复杂度在任何情况下都是 O(n log n),这使其在处理大规模数据时非常高效,但它的空间复杂度为 O(n),因为合并过程需要额外的数组来暂存数据。
下面的流程图清晰地展示了归并排序分与治的全过程:
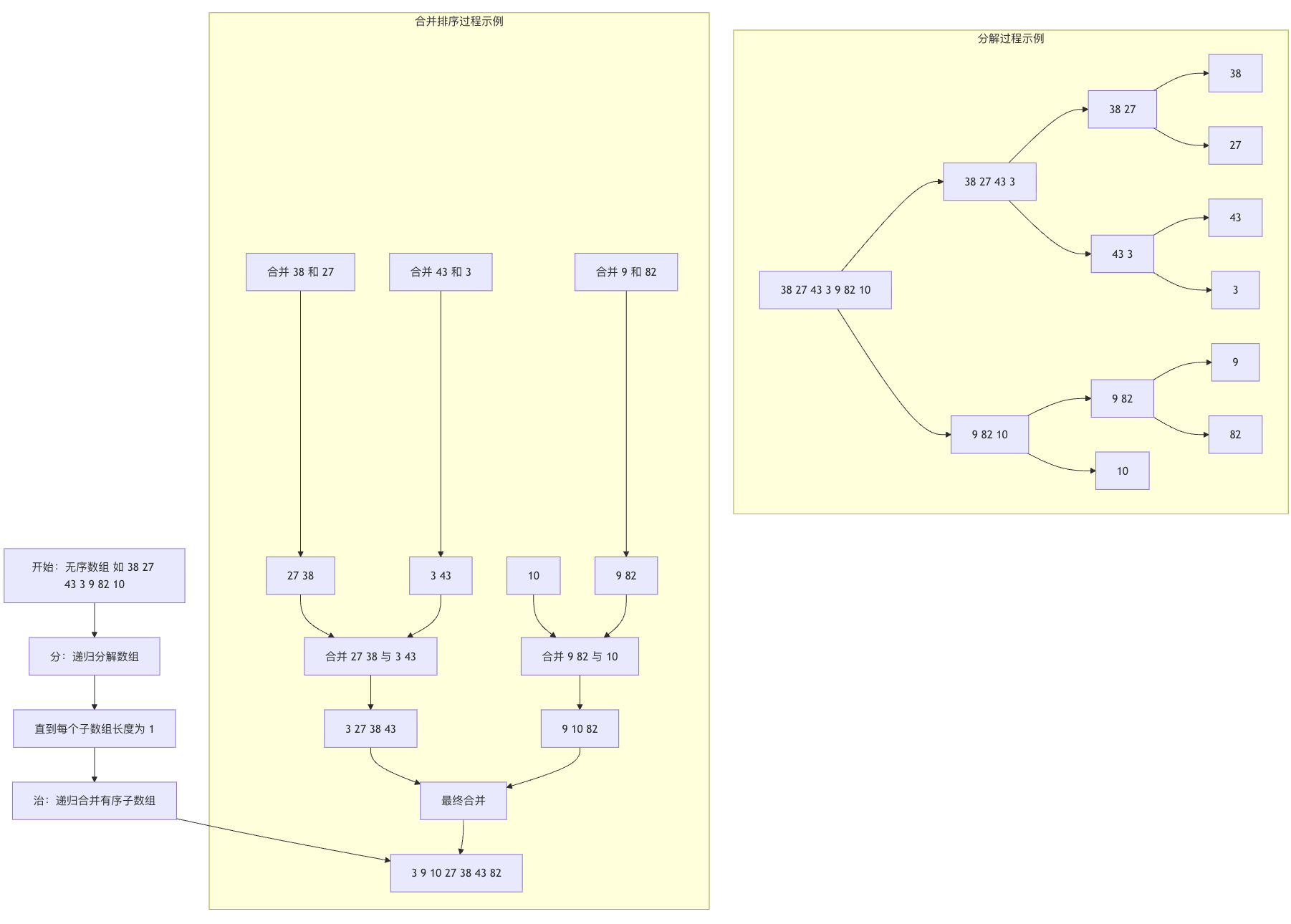
过程图示
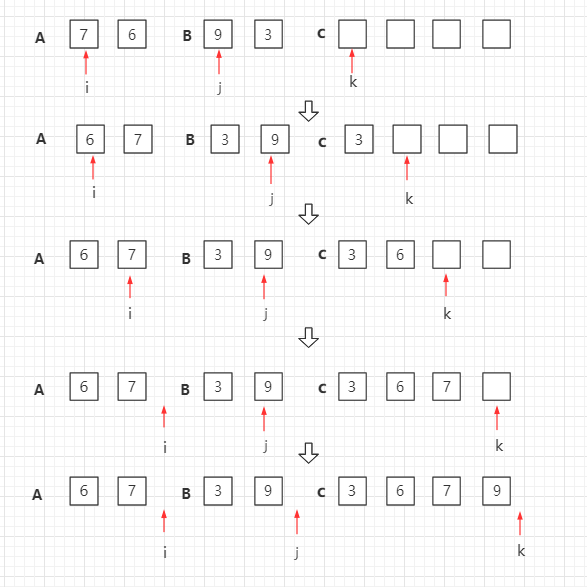
归并排序是递归算法的一个实例,这个算法中基本的操作是合并两个已排序的数组,取两个输入数组 A 和 B,一个输出数组 C,以及三个计数器 i、j、k,它们初始位置置于对应数组的开始端。
A[i] 和 B[j] 中较小者拷贝到 C 中的下一个位置,相关计数器向前推进一步。
当两个输入数组有一个用完时候,则将另外一个数组中剩余部分拷贝到 C 中。
自顶向下的归并排序,递归分组图示:
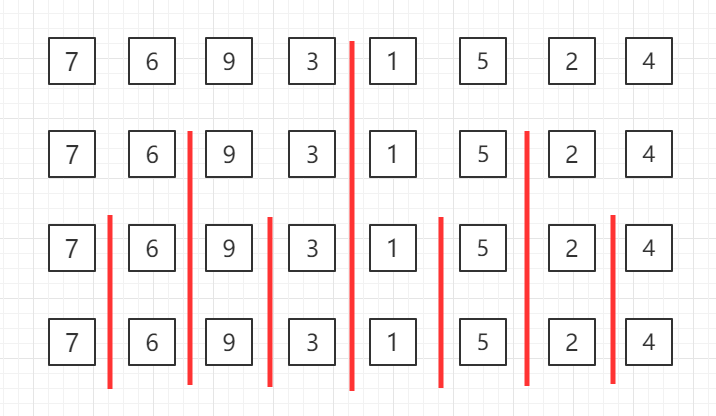
对第三行两个一组的数据进行归并排序
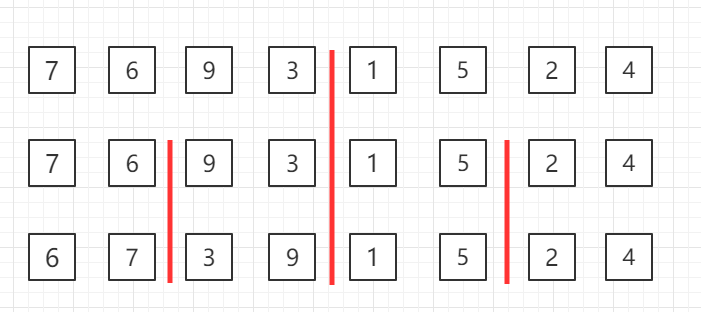
对第二行四个一组的数据进行归并排序
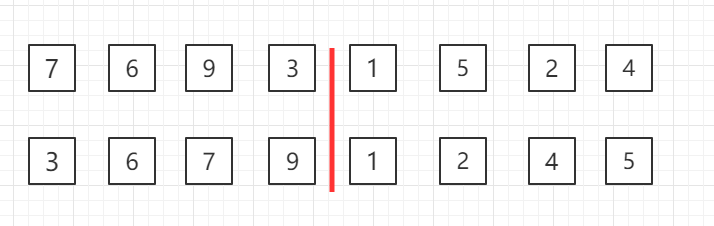
整体进行归并排序

Java 实例代码
源码包下载:Download
MergeSort.java 文件代码:
// 将arr[l...mid]和arr[mid+1...r]两部分进行归并
private static void merge(Comparable[] arr, int l, int mid, int r) {
Comparable[] aux = Arrays.copyOfRange(arr, l, r + 1);
// 初始化,i指向左半部分的起始索引位置l;j指向右半部分起始索引位置mid+1
int i = l, j = mid + 1;
for (int k = l; k <= r; k++) {
if (i > mid) { // 如果左半部分元素已经全部处理完毕
arr[k] = aux[j - l];
j++;
} else if (j > r) { // 如果右半部分元素已经全部处理完毕
arr[k] = aux[i - l];
i++;
} else if (aux[i - l].compareTo(aux[j - l]) < 0) { // 左半部分所指元素 < 右半部分所指元素
arr[k] = aux[i - l];
i++;
} else { // 左半部分所指元素 >= 右半部分所指元素
arr[k] = aux[j - l];
j++;
}
}
}
// 递归使用归并排序,对arr[l...r]的范围进行排序
private static void sort(Comparable[] arr, int l, int r) {
if (l >= r) {
return;
}
int mid = (l + r) / 2;
sort(arr, l, mid);
sort(arr, mid + 1, r);
// 对于arr[mid] <= arr[mid+1]的情况,不进行merge
// 对于近乎有序的数组非常有效,但是对于一般情况,有一定的性能损失
if (arr[mid].compareTo(arr[mid + 1]) > 0)
merge(arr, l, mid, r);
}
public static void sort(Comparable[] arr) {
int n = arr.length;
sort(arr, 0, n - 1);
}
// 测试MergeSort
public static void main(String[] args) {
int N = 1000;
Integer[] arr = SortTestHelper.generateRandomArray(N, 0, 100000);
sort(arr);
//打印数组
SortTestHelper.printArray(arr);
}
}
算法原理与步骤详解
归并排序的实现主要依赖于两个核心函数:merge_sort(负责"分")和 merge(负责"治")。
1. 分解函数 merge_sort
这个函数采用递归的方式工作:
基准情况:如果当前数组的长度小于等于 1,那么它已经是有序的,直接返回。
递归情况:
- 找到数组的中间位置
mid。 - 对左半部分
arr[:mid]递归调用merge_sort。 - 对右半部分
arr[mid:]递归调用merge_sort。 - 最后,调用
merge函数将已经排好序的左右两部分合并起来。
2. 合并函数 merge
这是算法的精髓所在,负责将两个已经有序的小数组合并成一个大的有序数组。过程类似于我们同时翻阅两本已经按字母排序的通讯录,合并成一本。
- 创建一个临时数组
temp,以及三个指针:i(指向左数组当前元素),j(指向右数组当前元素),k(指向临时数组的填充位置)。 - 比较
left[i]和right[j],将较小的那个元素放入temp[k],然后相应指针和k向前移动一步。 - 重复步骤 2,直到其中一个数组的所有元素都被放入临时数组。
- 将另一个数组中剩余的所有元素(它们本来就比已放入的元素大,且已有序)直接按顺序追加到临时数组的末尾。
- 将临时数组
temp中的有序序列复制回原数组的对应位置。
代码实现与逐行解析
让我们用 Python 来实现归并排序。我们将提供一个完整的、注释详尽的版本。
测试数据
首先,我们准备一个无序的列表作为测试数据:
实例
test_array = [38, 27, 43, 3, 9, 82, 10]
print("原始数组:", test_array)
完整实现
实例
"""
归并排序的主函数。
参数:
arr (list): 待排序的列表。
返回:
list: 排序后的新列表(为了清晰,本实现返回新列表)。
"""
# 基准情况:如果数组长度为0或1,则已经有序
if len(arr) <= 1:
return arr
# 1. 分:找到中间点,将数组分成两半
mid = len(arr) // 2
left_half = arr[:mid] # 左半部分
right_half = arr[mid:] # 右半部分
# 递归地对左右两半进行排序
left_sorted = merge_sort(left_half)
right_sorted = merge_sort(right_half)
# 2. 治:合并两个已排序的子数组
return merge(left_sorted, right_sorted)
def merge(left, right):
"""
合并两个已排序的列表。
参数:
left (list): 第一个已排序的列表。
right (list): 第二个已排序的列表。
返回:
list: 合并后的有序列表。
"""
sorted_list = [] # 用于存放合并结果的临时列表
i = j = 0 # i 和 j 分别是遍历 left 和 right 的指针
# 3. 比较并合并:当两个列表都还有元素时
while i < len(left) and j < len(right):
if left[i] <= right[j]: # 注意使用 <= 以保持排序的稳定性
sorted_list.append(left[i])
i += 1
else:
sorted_list.append(right[j])
j += 1
# 4. 处理剩余元素:将左列表或右列表中剩余的元素全部追加到结果中
# 由于 left 和 right 本身已有序,剩余的元素一定比已合并的元素都大
sorted_list.extend(left[i:])
sorted_list.extend(right[j:])
return sorted_list
# 使用测试数据运行算法
sorted_array = merge_sort(test_array.copy()) # 使用copy避免修改原数组
print("归并排序后:", sorted_array)
代码运行与输出
当你运行上面的代码时,你会看到如下输出:
原始数组: [38, 27, 43, 3, 9, 82, 10] 归并排序后: [3, 9, 10, 27, 38, 43, 82]
算法复杂度分析
理解一个算法的效率至关重要。我们通过下表来总结归并排序的性能:
| 指标 | 复杂度 | 说明 |
|---|---|---|
| 时间复杂度 | O(n log n) | 这是归并排序最显著的优势。log n 来自于递归的层数(将数组对半分),n 来自于每一层合并操作需要遍历所有元素。无论数据初始状态如何(最好、最坏、平均情况),时间复杂度都是 O(n log n)。 |
| 空间复杂度 | O(n) | 合并过程需要与原始数组等大的额外空间来存储临时数组。这是归并排序的主要缺点。 |
| 稳定性 | 稳定 | 在 merge 函数中,当 left[i] == right[j] 时,我们优先取 left[i](使用了 <= 比较),这保证了相等元素的原始相对顺序不变。 |
| 是否原地排序 | 否 | 需要额外的内存空间。 |