
希尔排序
希尔排序(Shell Sort)是插入排序的一种高效改进版本,由 Donald Shell 于 1959 年提出。
希尔排序的核心思想是通过将原始列表分割成多个子序列,先对每个子序列进行插入排序,然后逐步缩小子序列的间隔,最终对整个列表进行一次标准的插入排序。这种方法使得元素能够大跨度地移动,从而在早期阶段消除大量的逆序对,显著提升了排序效率。
想象一下整理一副乱序的扑克牌。插入排序就像一张一张地拿起牌,插入到手中已排序牌堆的正确位置。而希尔排序则像先每隔几张牌抽出来组成一个小牌堆并排序,然后缩小抽牌的间隔,重复这个过程。当间隔缩小到 1 时,就变成了标准的插入排序,但此时整个序列已经基本有序,最后的插入排序会非常快。
工作原理
希尔排序的关键在于一个称为 增量序列 的概念。增量序列决定了每次划分子序列的间隔。算法会按照一个逐渐减小的增量序列,对列表进行多轮排序。
算法步骤
- 选择增量序列:确定一个由大到小的整数序列,最后一个增量必须是 1。最常用的初始增量是数组长度的一半,然后逐次减半。
- 按增量分组:对于当前的增量
gap,将整个列表分成gap个子序列。每个子序列由所有间隔为gap的元素组成。 - 对子序列进行插入排序:分别对每个子序列进行插入排序。
- 减小增量:得到一个新的、更小的增量,重复步骤 2 和 3。
- 最终排序:当增量减小到 1 时,对整个列表进行一次标准的插入排序,此时列表已基本有序,排序很快完成。
适用说明
希尔排序时间复杂度是 O(n^(1.3-2)),空间复杂度为常数阶 O(1)。希尔排序没有时间复杂度为 O(n(logn)) 的快速排序算法快 ,因此对中等大小规模表现良好,但对规模非常大的数据排序不是最优选择,总之比一般 O(n^2 ) 复杂度的算法快得多。
过程图示
希尔排序目的为了加快速度改进了插入排序,交换不相邻的元素对数组的局部进行排序,并最终用插入排序将局部有序的数组排序。
在此我们选择增量 gap=length/2,缩小增量以 gap = gap/2 的方式,用序列 {n/2,(n/2)/2...1} 来表示。
如图示例:
(1)初始增量第一趟 gap = length/2 = 4
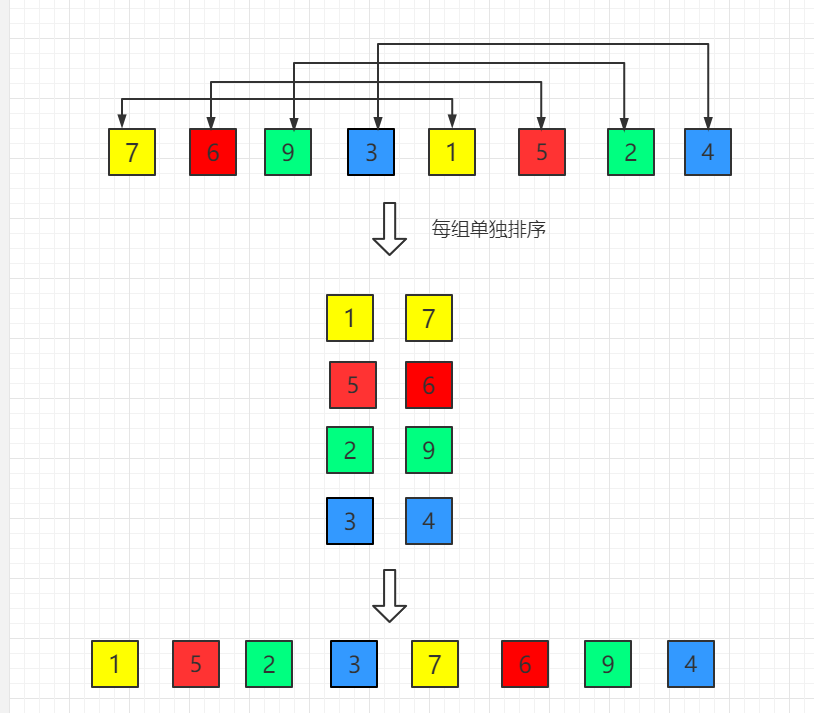
(2)第二趟,增量缩小为 2
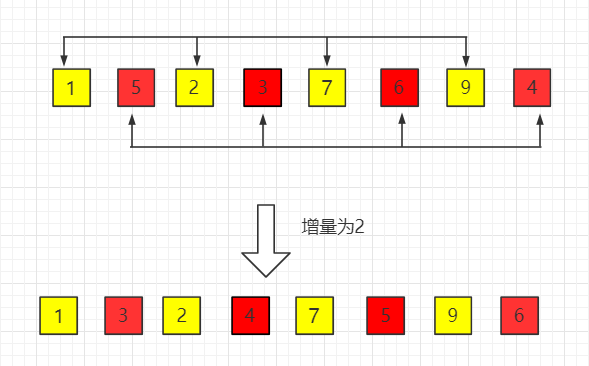
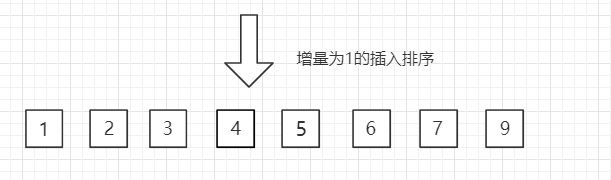
(3)第三趟,增量缩小为 1,得到最终排序结果
Java 实例代码
源码包下载:Download
最内层循环其实就是插入排序:
ShellSort.java 文件代码:
//核心代码---开始
public static void sort(Comparable[] arr) {
int j;
for (int gap = arr.length / 2; gap > 0; gap /= 2) {
for (int i = gap; i < arr.length; i++) {
Comparable tmp = arr[i];
for (j = i; j >= gap && tmp.compareTo(arr[j - gap]) < 0; j -= gap) {
arr[j] = arr[j - gap];
}
arr[j] = tmp;
}
}
}
//核心代码---结束
public static void main(String[] args) {
int N = 2000;
Integer[] arr = SortTestHelper.generateRandomArray(N, 0, 10);
ShellSort.sort(arr);
for( int i = 0 ; i < arr.length ; i ++ ){
System.out.print(arr[i]);
System.out.print(' ');
}
}
}
Python 算法实现
我们将使用 Python 来实现希尔排序,并采用最常见的增量设置(希尔原始序列):gap = n // 2,并持续对 gap 进行整除 2 操作,直到 gap 为 1。
实例
"""
使用希尔排序算法对列表进行原地升序排序。
参数:
arr (list): 待排序的列表。
返回:
list: 排序后的列表(原地修改,也返回)。
"""
n = len(arr)
# 初始增量 gap 设置为数组长度的一半
gap = n // 2
# 循环直到 gap 缩小到 0
while gap > 0:
# 从 gap 开始,对每个元素进行"插入排序"
# 注意:这里 i 从 gap 到 n-1,遍历的是所有元素
for i in range(gap, n):
# 将 arr[i] 保存到临时变量 temp
temp = arr[i]
j = i
# 对当前 gap 下的子序列进行插入排序
# 如果同一子序列中前面的元素大于 temp,则向后移动
while j >= gap and arr[j - gap] > temp:
arr[j] = arr[j - gap]
j -= gap
# 将 temp 插入到正确的位置
arr[j] = temp
# 减小增量,例如 gap 减半
gap //= 2
return arr
# 测试代码
if __name__ == "__main__":
# 测试数据 1: 随机乱序
test_array = [8, 3, 5, 1, 4, 2, 7, 6]
print("排序前:", test_array)
sorted_array = shell_sort(test_array.copy()) # 使用copy避免修改原数组
print("排序后:", sorted_array)
# 测试数据 2: 包含重复元素
test_array2 = [5, 2, 9, 5, 2, 3, 5]
print("\n排序前:", test_array2)
print("排序后:", shell_sort(test_array2.copy()))
# 测试数据 3: 逆序数组
test_array3 = [10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
print("\n排序前:", test_array3)
print("排序后:", shell_sort(test_array3.copy()))
代码解析:
def shell_sort(arr):定义希尔排序函数。n = len(arr)获取数组长度。gap = n // 2初始化增量。这是希尔排序最经典的增量序列起点。while gap > 0:外层循环,控制增量逐渐减小直到为 0(实际为 1 后执行完,gap //= 2变为 0 退出)。for i in range(gap, n):内层循环。从索引gap开始遍历。i指向的是当前待插入的元素。注意,这个循环巧妙地同时处理了所有以gap为间隔的子序列。temp = arr[i]和j = i:保存当前元素的值,并用j来记录它在当前子序列中应该插入的位置。while j >= gap and arr[j - gap] > temp:这是插入排序的核心。在同一个子序列内(通过j - gap索引访问前一个元素),如果前一个元素比temp大,就将前一个元素向后移动gap个位置。arr[j] = temp:将保存的temp值插入到正确的位置。gap //= 2:一轮排序结束后,将增量减半,进行下一轮更精细的排序。return arr:返回排序后的数组。
增量序列的选择
增量序列的选择直接影响希尔排序的性能。上面我们使用的是 Shell 原始序列(n/2, n/4, ..., 1),但并非最优。下面介绍几种常见的增量序列:
| 序列名称 | 生成公式 | 特点与复杂度 |
|---|---|---|
| Shell 原始序列 | $gap = \lfloor \frac{n}{2} \rfloor, gap = \lfloor \frac{gap}{2} \rfloor...$ | 实现简单,最坏时间复杂度为 $O(n^2)$。 |
| Hibbard 序列 | $1, 3, 7, 15, ..., 2^k - 1$ | 最坏时间复杂度可提升至 $O(n^{3/2})$。 |
| Knuth 序列 | $1, 4, 13, 40, ..., (3^k - 1) / 2$ (小于 n) | 平均时间复杂度约为 $O(n^{1.25})$,实践中常用。 |
| Sedgewick 序列 | $1, 5, 19, 41, 109, ...$ (混合了 $9 \times 4^k - 9 \times 2^k + 1$ 和 $4^k - 3 \times 2^k + 1$) | 是目前已知最好的序列之一,最坏复杂度可达 $O(n^{4/3})$。 |
使用 Knuth 序列的实现示例
实例
n = len(arr)
# 生成 Knuth 增量序列: 1, 4, 13, 40, 121, ...
gap = 1
while gap < n // 3:
gap = 3 * gap + 1 # 生成最大的初始增量
while gap > 0:
for i in range(gap, n):
temp = arr[i]
j = i
while j >= gap and arr[j - gap] > temp:
arr[j] = arr[j - gap]
j -= gap
arr[j] = temp
gap //= 3 # Knuth 建议每次除以 3
return arr
# 测试 Knuth 序列版本
test_array = [33, 12, 56, 78, 2, 45, 67, 89, 1, 23]
print("Knuth序列排序前:", test_array)
print("Knuth序列排序后:", shell_sort_knuth(test_array.copy()))
算法特性与复杂度分析
时间复杂度
希尔排序的时间复杂度分析非常复杂,因为它依赖于所选择的增量序列。
- 最坏情况: 使用 Shell 原始序列时,最坏时间复杂度为 $O(n^2)$。
- 平均情况: 对于较好的增量序列(如 Knuth, Sedgewick),平均时间复杂度在 $O(n^{1.25})$ 到 $O(n^{1.5})$ 之间。
- 最好情况: 当数组已经有序时,复杂度可以接近 $O(n \log n)$。
空间复杂度
- 希尔排序是 原地排序 算法,只需要常数级别的额外空间(如
temp,gap,i,j等变量),因此空间复杂度为 $O(1)$。
稳定性
- 希尔排序是 不稳定 的排序算法。因为在按增量分组排序时,相同的元素可能会被分到不同的子序列中,并因移动而改变相对顺序。
与其他排序算法的简单对比
| 特性 | 希尔排序 | 插入排序 | 归并排序 | 快速排序 |
|---|---|---|---|---|
| 平均时间复杂度 | $O(n^{1.25})$ ~ $O(n^{1.5})$ | $O(n^2)$ | $O(n \log n)$ | $O(n \log n)$ |
| 空间复杂度 | $O(1)$ | $O(1)$ | $O(n)$ | $O(\log n)$ |
| 稳定性 | 不稳定 | 稳定 | 稳定 | 不稳定 |
| 优点 | 中等数据量表现好,原地排序 | 简单,小数据或基本有序时高效 | 稳定,时间复杂度优 | 平均情况下最快 |
| 缺点 | 复杂度分析难,增量序列选择影响大 | 大数据量效率低 | 需要额外空间 | 最坏情况退化为 $O(n^2)$ |